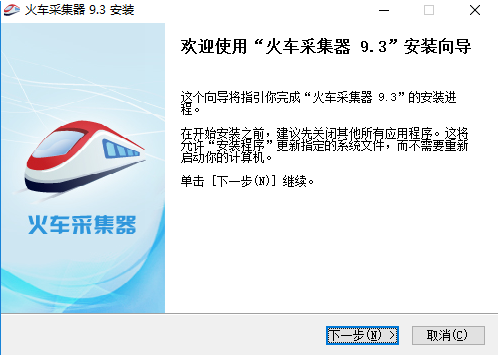
- 在本站下载火车头采集器的压缩包,然后双击运行它。
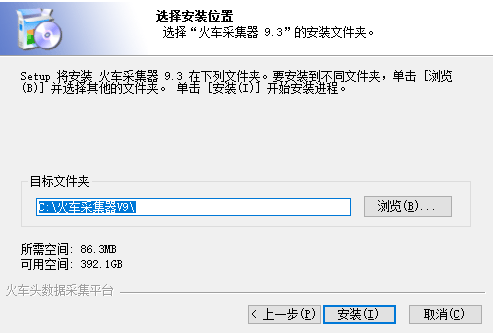
- 单击浏览以设置软件位置,然后单击安装。
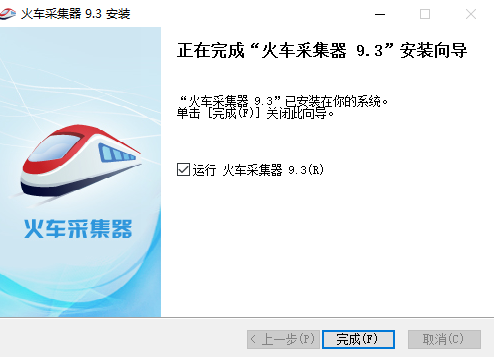
- ;一段时间后,安装将成功。如果需要立即使用它,请检查[运行中的火车头采集器最后单击[完成]。
- 在主程序界面中,单击“新建”(New)下拉箭头,然后选择“任务”(Task)。
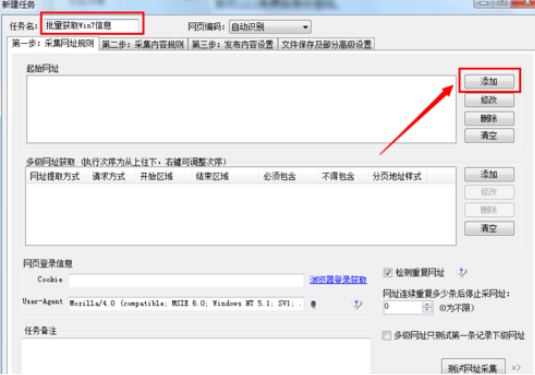
五、在弹出窗口中,输入“任务名称”,然后单击“起始URL”列右侧的“添加”按钮。
六、另一个非常重要的步骤是将要收集的网站划分为表格,分析网站上每篇文章的URL并找出规则,最后填写如图所示的表格。
七、然后切换至标签“步骤2:收集内容规则”。我们需要拆分网络内容。以“搜狗浏览器”为例,右键单击网页进行分析,然后从弹出菜单中选择“评论元素”。
八、在界面的“开发模式”中,单击“在透视图中选择选项卡”按钮,然后单击“标题”内容,然后在“开发人员”窗口中将显示与标题对应的标签,例如“ H2”。
九、接下来,在“内容收集规则”界面中,单击“添加”以添加“标题”,或直接双击“标题”进行编辑。在弹出的界面中,选中“剪切前后”和“分别。
十、使用相同的方法来完成其他内容收集规则,切换到“步骤3:发布内容设置”选项卡,选中“启用方法2”并进行设置,如图所示。
十一、最后,从任务列表中,检查要收集的内容,然后单击“开始”按钮,根据规则在网站上收集网站的内容。